lxml is the most feature-rich and easy-to-use library for processing XML and HTML in the Python language.
我们这里介绍lxml库和XPath语法来帮助我们完成信息的提取。
本文Python代码版本2.7
XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历,我们用来提取格式为HTML的网页源码效率也相当高,可以遍历html的各个标签和属性,来定位到我们需要的信息的位置,并提取。
1,安装
需要安装lxml库
pip install lxml
2,语法
举 例子之前来个常规语法介绍。详细可参见W3school的XPath语法介绍。
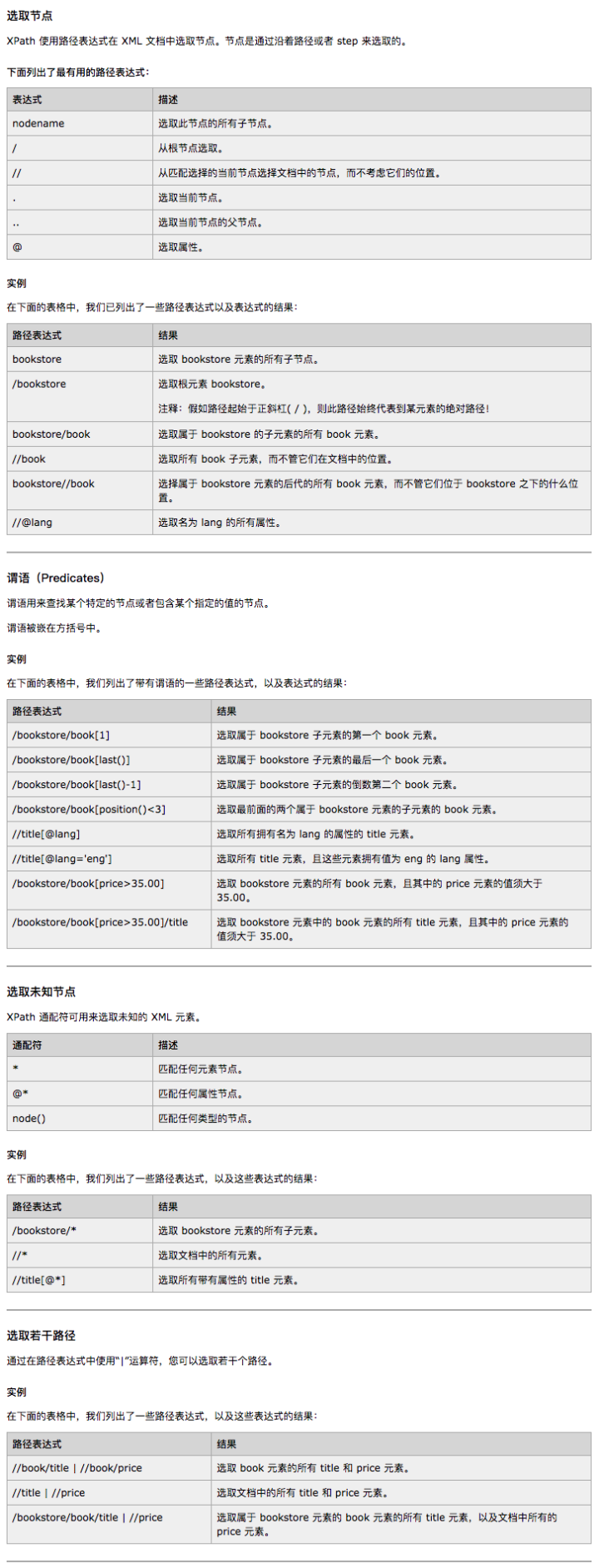
3,案列说明
直接来个案例吧。这个网址:豆瓣电影排行榜
这里用谷歌浏览器打开开发者工具查看网页源代码(windows在谷歌浏览器界面按F12或者‘设置 -> 开发者工具’。Mac用户两个手指轻点页面-> “检查”)
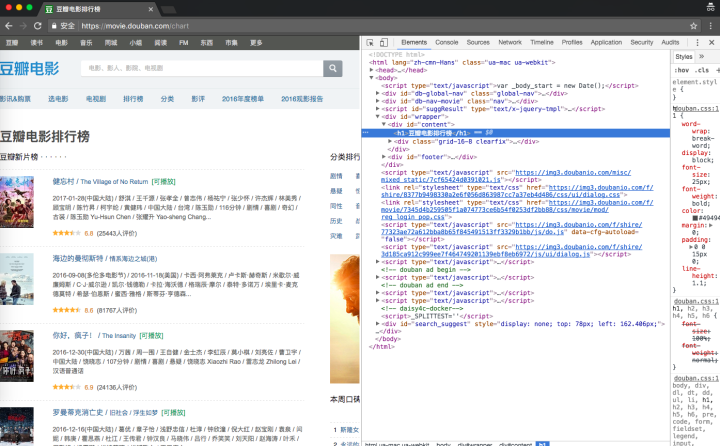
鼠标移动到“豆瓣电影排行榜”,对应右边的开发者工具就会选中相应的标签,即图中的:
1
<h1>豆瓣电影排行榜</h1>
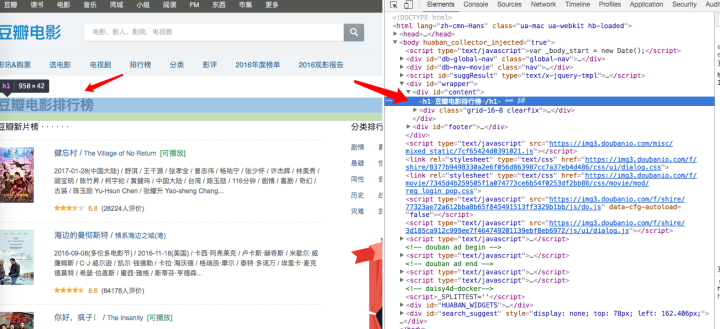
那我们试着用xpath来获取这个这个h1标签:
# coding:utf-8
import requests
# 上节的requests请求网页,得到网页源代码
url = 'https://movie.douban.com/chart'
r = requests.get(url).content
# 导入lxml库和html.fromStringh函数来解析html
from lxml import html
# 调用html.fromString函数解析html源代码
sel = html.fromstring(r)
# 提取h1标签,text()获取该标签下的文本
title = sel.xpath("//h1/text()")
#这里返回的类型列表,而这个网页中只有一个h1标签,索引为0来得到title
print type(title)
print title[0]
打印出来就得到我们需要的h1标签的标题:
1
2
# <type 'list'>
# 豆瓣电影排行榜
再来看看提取属性方法,例如下面的这些电影的链接列表,是在a标签中的href属性中。
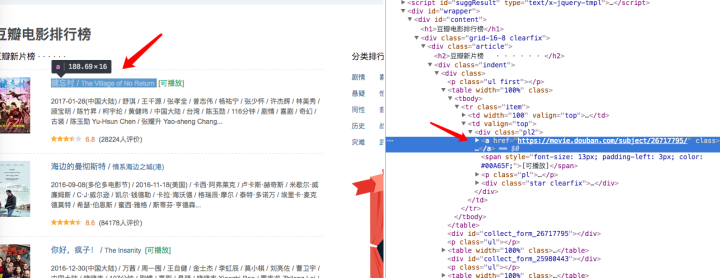
要想精确的定位到该标签,我们能可以先定位到这个a标签的父标签div,
1
<div class="pl2">...</div>
因此可以写成:
# coding:utf-8
import requests
from lxml import html
url = 'https://movie.douban.com/chart'
r = requests.get(url).content
sel = html.fromstring(r)
# 提取h1标签
title = sel.xpath("//h1/text()")
# 提取链接
links = sel.xpath('//div[@class="pl2"]/a/@href')
# 上面返回的是所有符合条件的链接的列表,for循环来读取一下
for link in links:
print link
控制台打印输出:
4,最后
以上就是xpath的常见的用法,提取网页信息一个高效的工具。大家可以试试提取这个网站的电影名称,评分等等信息来练练手。
1,lxml官方文档:Processing XML and HTML with Python
2,w3school的xpath语法教程:XPath 教程